Abstract
Past efforts towards the creation of Part-of-Speech (POS) taggers using machine-learning techniques have been largely successfully, but not without significant costs. Utilizing proper lexical works, these attempts have often made use of tailored output sets—manually and expensively parsed by hand. As such, these approaches have rendered a huge body of data inaccessible, and it is precisely as data continues to grow at an exponential rate that finding better ways to make use of data have become increasingly relevant. Herein I use conversational data as a means by which to create an input-output space, and by mining Twitter, create a set of trainable data that uses simplistic and exclusionary parsing rules in an attempt to classify words appearing in difficult-to-parse contexts using kNN.
Data collection utilized the Twitter REST API, searching for Tweets containing ambiguous words. For each ambiguous term, a query was conducted so as to ascertain the most replied-to tweets containing these terms, after which, the author’s profile was then searched against in order to find replies that also contained the search term. Each conversation was then parsed into a number of trainable instances, utilizing the outcome of the instance in the conversation that, when parsed using simplistic exclusionary rules, yielded the lowest entropy. This project has made use of a bag-of-words style approach, with each instance including a list of ids corresponding to the tokens occurring within the sentence. Each instance also kept track of which words were immediately before and after the search term’s instantiation.
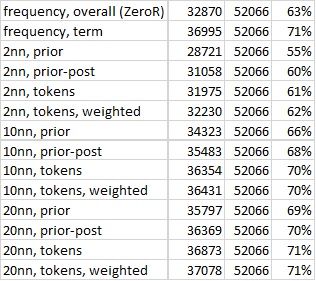
K-Nearest-Neighbor (kNN) was settled upon for use in the experiment, the decision resting largely upon the constraints of the project as well as the relative ease in implementing kNN, its extensibility, and the specialized nature of the collected data. With a generic kNN implementation thus established, a series of different distance measures were then applied with varying success. While the distance measures were able to outperform a blanket ZeroR measure by—in the best case—8 percent, none of the measures were able to significantly outperform a similar measure instead restricted to per-term frequency.